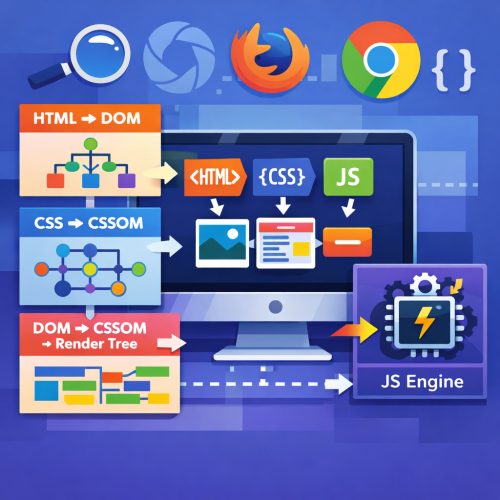
Beim Laden einer Webseite verarbeitet der Browser unterschiedliche Sprachen wie HTML, CSS und JavaScript und wandelt sie in sichtbare Inhalte um. Er arbeitet dabei im Kern wie ein Interpreter: Code wird eingelesen, geprüft und direkt ausgeführt.
Moderne Browser nutzen dafür mehrere Schritte:
- HTML wird zum DOM,
- CSS zum CSSOM,
- daraus entsteht der Render-Tree,
JavaScript läuft in einer Engine, die Code interpretiert und bei Bedarf per JIT optimiert.
Typische Fehlinterpretationen im Browser
- Unterschiedliche Browser-Implementierungen
Nicht jeder Browser setzt HTML-, CSS- und JavaScript-Standards gleich um. Das führt zu abweichenden Layouts, unterschiedlichen Default-Werten oder speziellen Bugs (z. B. bei Flexbox oder Grid). - Mehrdeutiger oder fehlerhafter Code
Ungeschlossene Tags, widersprüchliche CSS-Regeln oder JavaScripts automatische Typumwandlungen können dazu führen, dass der Browser „rät“, was gemeint war – und das Ergebnis anders aussieht als erwartet. - Übersetzungsfunktionen
Automatische Übersetzungen im Browser können Fachbegriffe, UI-Texte oder Beschriftungen falsch übertragen und dadurch Inhalte verfälschen. - Falsche Interpretation von Daten
Analytics-Daten oder Logs werden im Frontend oft falsch gelesen, z. B. wenn man Messlogiken nicht kennt oder Filter falsch gesetzt sind.
Lösung
- Fehlinterpretationen vermeiden
- sauberen, validen Code schreiben
- Standards einhalten
- in mehreren Browsern testen
- Layout und Verhalten klar definieren
- Mess- und Trackinglogik verständlich dokumentieren
Ein sauber strukturierter, standardkonformer Code ist die Grundlage für eine verlässliche Darstellung und Funktion einer Webseite. Nur wer Browserverhalten, Unterschiede in der Interpretation und mögliche Übersetzungsfehler kennt, kann konsistente Ergebnisse erzielen. Gründliches Testen und eine präzise Dokumentation sichern nicht nur die technische Stabilität, sondern auch die Verständlichkeit und Benutzerfreundlichkeit der Anwendung.